Idioms for the D Programming Language
ἰδῐόω (idióō): peculiarity, specific property, unique feature.
/// Returns: Most precise clock ticks, in microseconds (us).
long getTickUs() nothrow @nogc
{
import core.time;
return convClockFreq(MonoTime.currTime.ticks, MonoTime.ticksPerSecond, 1_000_000);
}
core.time.MonoTime.currTime() returns the most precise available clock.
/// Returns: Most precise clock ticks, in milliseconds.
long getTickMs() nothrow @nogc
{
import core.time;
return convClockFreq(MonoTime.currTime.ticks, MonoTime.ticksPerSecond, 1_000);
}
This idiom by Stephane Ribas.
Installing the D programming language on Windows can be sometimes difficult. This guide is intended to provide a beginner-friendly tutorial for foolproof D installation, using Visual Studio + VisualD.
The order of the steps is important!
Before starting the D language installation, we recommend you to install FIRST the Microsoft Visual Studio Community IDE:
To do so you will have to install Microsoft Visual Installer that can be downloaded from Microsoft Visual Studio official website.
Once you have downloaded this executable and installed it on your PC, launch it and install the free Microsoft Visual Studio Community Edition (2022 version or above).
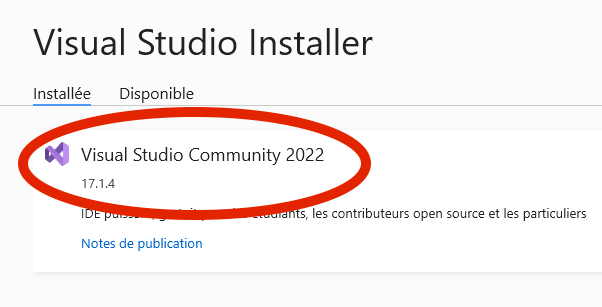
IMPORTANT: Once installed, you need to install Windows SDK and C/C++ libs. Check "C/C++ desktop" choice in the VS installer.
IMPORTANT: On Windows arm64, use Visual Studio 2022+ (or paid Visual Studio 2019), LDC 1.41 or later, and VisualD 1.40 or later. Use then the "Visual Studio" debugger.
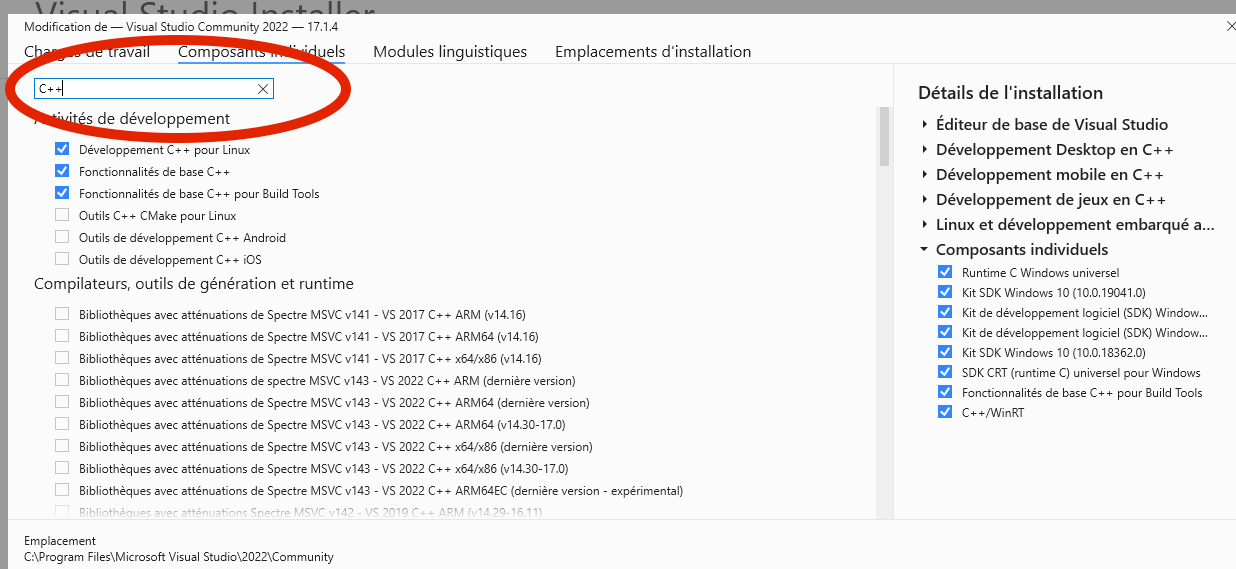
Open again the Microsoft Visual Installer & in Microsoft Visual Studio Community area, click on the "MODIFY" option
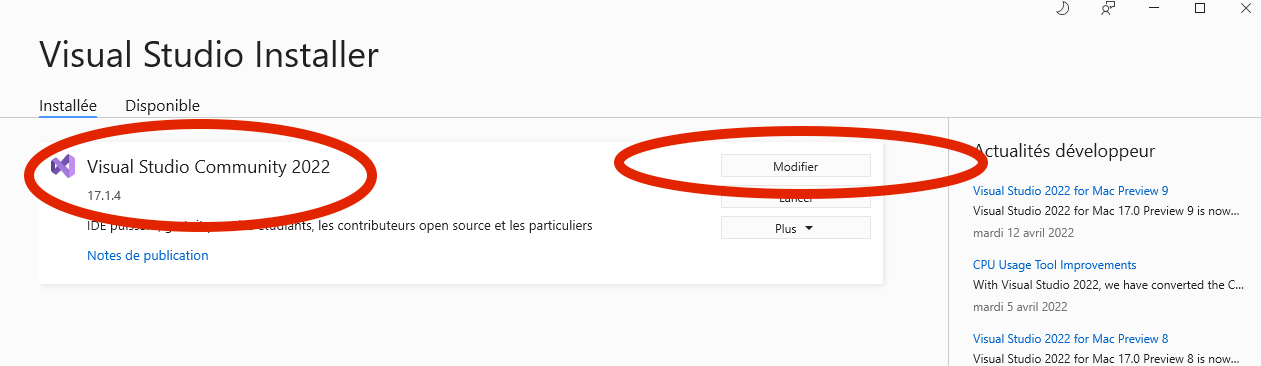
Choose the thumbnail called "Individual component':
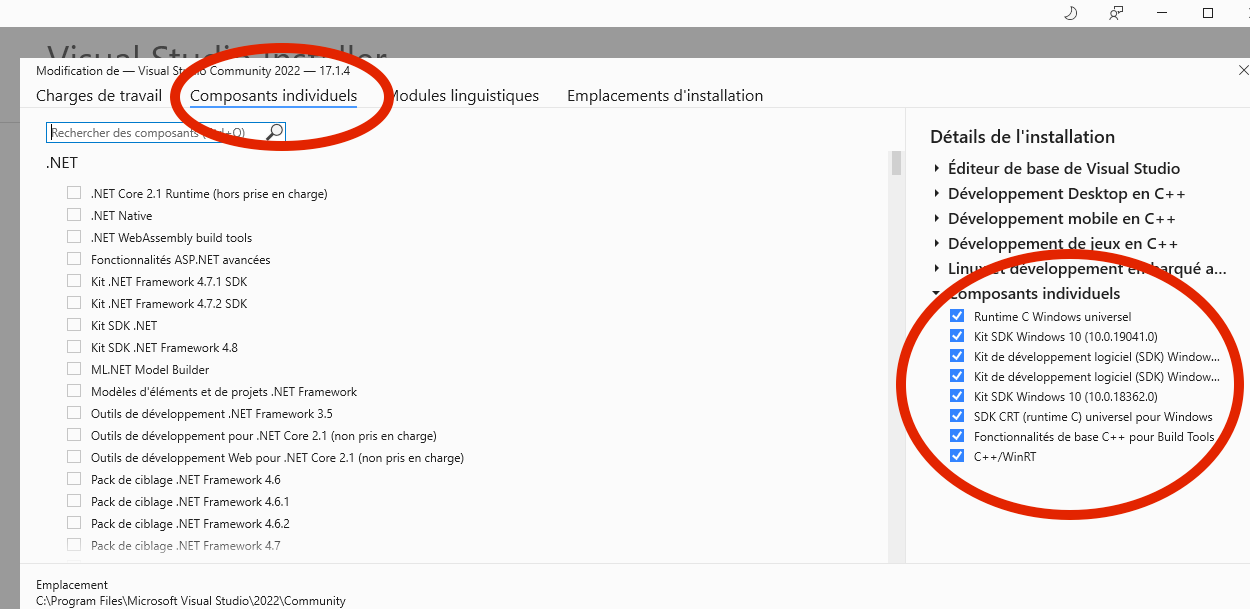
In the SEARCH toolbar, write "Windows SDK" and press ENTER:
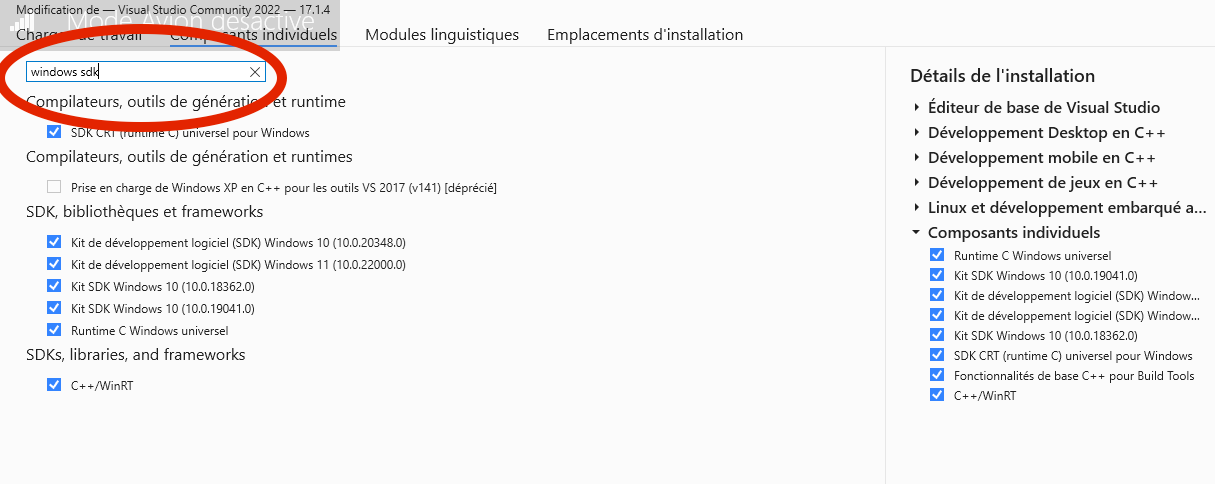
The program will show you all the Windows SDK libraries that you can install on your system.
Install ALL OF THEM. It's not clear how many Windows SDK you need, probably you need just one. But it's better safe than sorry!
Now you have an IDE & libs installed. Perfect!
Explanation: D programs links with both the D runtime, and a C runtime. Here the C runtime is MSVCRT (Visual C language runtime), so we need to install it.
PATH environment variableNormally, the Visual D installer should have already set up the PATH environment variable, adding the path to ldc2.exe:
You can check this by opening the environment variable setup in your system:
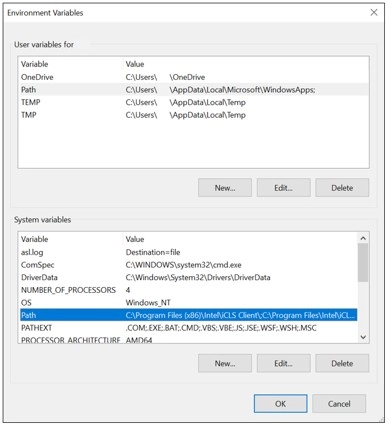
If you have the LDC path in your PATH variable: nothing else to do!
Otherwise, follow the instructions below:
If you don't want to do this (you are not lazy) :
Go the the Windows Configuration Panel, search for "environment variables" & add into the PATH the path to the LDC root folder:
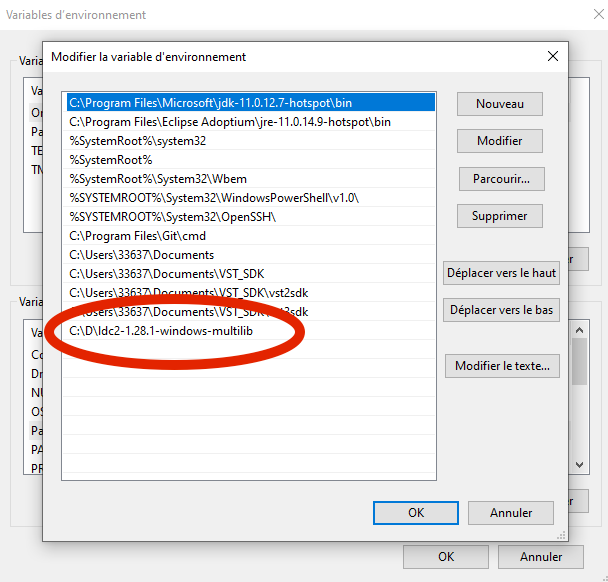
Here is a detailed guide to set your environment variables: https://www.computerhope.com/issues/ch000549.htm
Note: Environment variables are inherited from parent process to child process. After modifying them, you will have to restart your IDE, or terminal window, in order for them to udpate.
**Pro-tip:** Use WIN+R then type `sysdm.cpl` to setup environment variables.
Open a CMD.exe and try dub --version. You should get an answer from the system with a version number. You can now start writing D code & compile it!
Some useful commands:
dub -a x86 builds a 32-bit program using LDC
dub -a x86_64 builds a 64-bit program using LDC
dub -a x86 --compiler dmd builds a 32-bit program using DMD
dub -a x86_64 --compiler dmd builds a 64-bit program using DMD
dub generate visuald generates a 64-bit LDC VisualD solution.
dmd --version tells your DMD version.
ldc2 --version tells your LDC version.
rdmd file.d builds and run a single-file D program in file.d.
Warning: both DMD and LDC comes with their own dub. The one that is used depends on who is first in the PATH envvar.
In case you encounter an issue while installing the D programming language, do not hesitate to post your questions on the D.learn forum: https://forum.dlang.org/group/learn
The most vexing limitation of @nogc is that array literals generally can't be used anymore.
void main() @nogc
{
// Works: the array literal is used as a value.
int[3] myStaticArray = [1, 2, 3];
// Doesn't work.
int[] myDynamicArray = [1, 2, 3]; // Error: array literal in @nogc function
// may cause GC allocation
}
Indeed, such literals may well allocate a new array on the GC heap.
Fortunately, like often in the D world, there is an easy work-around to lift the limitations.
T[n] s(T, size_t n)(auto ref T[n] array) pure nothrow @nogc @safe
{
return array;
}
void main() @nogc
{
auto tmp = [1, 2, 3].s; // Create the static array on the stack
int[] myDynamicArray = tmp[]; // Slice that static array which is on stack
// Use myDynamicArray...
}
That work-around slices the stack allocated array and turn it into a slice. This would lead to memory corruption if the reference escapes.
Do not fear! The compiler warns you of escaped references to the stack, even in unsafe D.
// This function is illegal
int[] doNotDoThat() @nogc
{
return [1, 2, 3].s; // Error: escaping reference to stack allocated
// value returned by s([1, 2, 3])
}
Instead, duplicate this slice @nogc-style, for example with malloc. You are now able to use array literals in @nogc code.
This idiom originated from Randy Schütt.
Solution: Use the arsd-official:cgi package.
dub.json{
"name": "simple-HTTP-server",
"dependencies":
{
"arsd-official:cgi": "~>10.0"
}
}
index.html<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello</h1>
<p>This page brought to you by D.</p>
</body>
</html>
source/main.dstatic import std.file;
import arsd.cgi;
import std.format;
import std.stdio;
void myHTTPServer(Cgi cgi)
{
string url = cgi.pathInfo;
writefln("GET %s", url);
switch(cgi.pathInfo)
{
case "/style.css":
cgi.setResponseContentType("text/css");
cgi.write("body { color: red; }");
break;
case "/":
cgi.setResponseContentType("text/html");
cgi.write(std.file.read("index.html"));
break;
default:
cgi.setResponseStatus(404);
}
cgi.close();
}
mixin GenericMain!myHTTPServer;
dub -- --port 8080 then open http://localhost:8080/.
Get cgi.d documentation here.
Get the source code for all DIID examples here.
One of the most suprisingly effective optimization is to merge your array allocations together, if they have a chance to be accessed together.
You can do that with eg. MergedAlloc, a handy way to do that in an aggregate, that supports alignment, does the memory reclaim, and supports both pointers and slices.
Consider the following struct. It process things with intermediate buffers, who themselved have alignment requirements.
struct A
{
float[] buf0;
int[] buf1;
double* buf2;
void init(int n)
{
// allocate arrays
buf0 = allocateAligned!float(n, 16);
buf1 = allocateAligned!int(n, 16);
buf2 = allocateAligned!double(n, 16).ptr;
}
~this()
{
// reclaim memory
deallocate(buf0);
deallocate(buf1);
deallocate(buf2);
}
void process(float[] input)
{
// Do things with buf0, buf1, buf2, and input
}
}
Let's introduce MergedAlloc instead to have all the arrays in a single malloc call.
struct A
{
float[] buf0;
int[] buf1;
double* buf2;
MergedAllocation mergedAlloc;
void init(int n)
{
mergedAlloc.start(); // initialize merged alloc counter
layout(n); // first layout call count the bytes
mergedAlloc.allocate(); // make single allocation
layout(n); // second layout call sets the final pointers
}
void layout(int n)
{
mergedAlloc.allocArray(buf0, n, 16);
mergedAlloc.allocArray(buf1, n, 16);
mergedAlloc.alloc(buf2, n, 16);
}
void process(float[] input)
{
// Do things with buf0, buf1, buf2, and input
}
}
The layout functions is called twice:
0, and simply count the bytes
MergedAlloc implementationSee its source code.
Solution: Use the dplug:graphics package.
dub.json{
"name": "write-current-date-on-png",
"dependencies":
{
"dplug:graphics": "~>12.0"
}
}
This program assumes input.png and VeraBd.ttf in the project directory.
source/main.dstatic import std.file;
import std.datetime;
import dplug.graphics;
void main(string[] args)
{
// Load image.
auto image = loadOwnedImage( std.file.read("input.png") );
// Load font.
auto font = new Font( cast(ubyte[]) std.file.read("VeraBd.ttf") );
// Write text.
RGBA red = RGBA(255, 0, 0, 255);
float textX = 20;
float textY = 20;
float fontSize = 16;
string timeStr = Clock.currTime().toISOExtString();
image.toRef.fillText(font, timeStr, fontSize, 0.0, red, textX, textY, HorizontalAlignment.left);
// Save image.
std.file.write("output.png", image.toRef.convertImageRefToPNG);
}
Get dplug:graphics documentation here.
Get the source code for all DIID examples here.
Alternative: arsd solution.
Solution: Use the console-colors package.
dub.json{
"name": "colorize-text-output",
"dependencies":
{
"console-colors": "~>1.0"
}
}
source/main.dimport consolecolors;
void main()
{
cwriteln("This is light blue on orange".lblue.on_orange);
cwritefln("This is a <red>%s</red>.", "nested <yellow>color</yellow> string");
}
Get console-colors documentation here.
Get the source code for all DIID examples here.
Solution: Use std.getopt from Phobos.
dub.json{
"name": "cmdline-args",
"dependencies": {
}
}
source/main.dimport std.getopt;
int main(string[] args)
{
string data = null;
int length = 24;
bool verbose;
enum Color { no, yes }
Color color;
auto helpInformation = getopt(
args,
"length", &length, // numeric
"file", &data, // string
"verbose", &verbose, // flag
"color", "Information about this color", &color); // enum
// std.getopt always add an option for --help|-h
if (helpInformation.helpWanted || data is null)
{
defaultGetoptPrinter("Usage:", helpInformation.options);
return 1;
}
// do things...
return 0;
}
Get std.getopt documentation here.
Get the source code for all DIID examples here.
/+ +/ nestable comments and version(none)In addition to single-line comments // and block comments /* */, D supports nestable block comments with /+ +/.
/+
This whole block is commented.
/**
* A documented function.
*/
void doStuff()
{
// blah blah
}
/+
Such block comments are nestable.
+/
+/
They are handy when commenting large swaths of code. It would be the D equivalent to #if 0 / #endif pairs in C or C++.
If you prefer the commented portion of code to stay valid, prefer using version(none).
version(none)
{
// This whole block is commented, but still must parse.
/**
* A documented function
*/
void doStuff()
{
// blah blah
}
}
Indeed, none is a special version identifier that cannot be set.
version = none; // Error: version identifier 'none' is reserved and cannot be set
Appending an element to a dynamic array:
T[] arr;
arr ~= value; // value is pushed at the back of the array
Removing an element from a dynamic array given an index:
import std.algorithm : remove;
T[] arr;
arr = arr.remove(index); // index-th element is removed from array
Removing an element from a dynamic array given a value:
auto removeElement(R, N)(R haystack, N needle)
{
import std.algorithm : countUntil, remove;
auto index = haystack.countUntil(needle);
return (index != -1) ? haystack.remove(index) : haystack;
}
int[] arr = [1, 5, 10];
arr = arr.removeElement(5);
assert(arr == [1,10]);
Adding an element into an associative array:
aa[key] = value; // aa[key] is created if not already existing
Removing an element from an associative array given a key:
aa.remove(key); // there is a builtin property to do that
assert(false) is specialassert(false), assert(0), assert(null), or any other falsey expression at compile-time does not produce a regular assert.
Instead it is an instruction to crash the program, and is not removed in -release mode.
string getStuff()
{
if(expr)
return "something";
assert(1 < 0); // also possible, but "assert(0)" is typically used
// no return needed, since we just crashed
}
assert(false) (or an equivalent) also means that the current branch of the function doesn't need to return anything since the program will always crash when the assertion is reached.
It does not mean unreachable code, it means crash now and the compiler will never remove it.
Since assert(false) never get removed, it can be used to create a persistent assertion.
if (!cond)
assert(false); // will never be removed by the compiler in -release builds
assert(false) is fit for finding bugs, but not for input errors. In this case, prefer the use of std.exception.enforce.
A pure, nothrow, @nogc or @safe function can only call functions that are respectively pure, nothrow, @nogc or @safe/@trusted.
int plusOne(int a)
{
return a + 1;
}
void f() pure nothrow @nogc @safe
{
// Error: pure function 'f' cannot call impure function 'plusOne'
// Error: safe function 'f' cannot call system function 'plusOne'
// Error: @nogc function 'f' cannot call non-@nogc function 'plusOne'
// Error: 'plusOne' is not nothrow
plusOne(3);
}
However, function templates have their attributes automatically inferred.
int plusOne(int b = 2)(int a)
{
return a + 1;
}
void f() pure nothrow @nogc @safe
{
plusOne(3); // everything fine
}
Function templates bodies are always available to the compiler. Which is not the case for non-templated functions, who could be extern.
For consistency, non-templated functions attributes don't get inferred, even if the source code is available.
See also: https://dlang.org/spec/function.html#function-attribute-inference
@nogc is a function attribute which ensures a function never allocates through the GC.
void processStuff(double[] data) @nogc
{
double[] tempBuffer;
// Error: setting 'length' in @nogc function processStuff may cause GC a
tempBuffer.length = data.length;
...
}
Using @nogc is a must for memory-conscious code sections or for real-time threads.
However, not all library functions that could be marked @nogc are. At one point, you'll probably want to call functions as if they were @nogc. Here's how to do it:
import std.traits;
// Casts @nogc out of a function or delegate type.
auto assumeNoGC(T) (T t) if (isFunctionPointer!T || isDelegate!T)
{
enum attrs = functionAttributes!T | FunctionAttribute.nogc;
return cast(SetFunctionAttributes!(T, functionLinkage!T, attrs)) t;
}
// This function can't be marked @nogc but you know with application knowledge it won't use the GC.
void funcThatMightUseGC(int timeout)
{
if (unlikelyCondition(timeout))
throw new Exception("The world actually imploded.");
doMoreStuff();
}
void funcThatCantAffortGC() @nogc
{
// using a casted delegate literal to call non-@nogc code
assumeNoGC( (int timeout)
{
funcThatMightUseGC(timeout);
})(10000);
}
Regular expressions are found in the std.regex Phobos module.
import std.regex;
import std.stdio;
void main(string[] args)
{
auto re = regex(`My name is (\w+)\. I work for ([A-Za-z ]+)\.`);
string input = "My name is Kobayashi. I work for Keyser Soze.";
if (auto captures = matchFirst(input, re))
{
// There is a trap there, capture[0] is the whole matched string
writefln("First capture = %s", captures[1]);
writefln("2nd capture = %s", captures[2]);
}
}
ctRegex instead of regex builds the regular expression at compile-time, trading off compile-time speed for runtime speed.
auto re = ctRegex!(`My name is (\w+)\. I work for ([A-Za-z ]+)\.`); // automaton built at compile-time
In January 2016, an anonymous programmer posted on the D forums a Proof-of-Concept for a devious compile-time Random Number Generator.
/+ CTRNG
Proof-Of-Concept Compile-Time Random Number Generator.
Please never actually use this or anything like it.
While doing some metaprogramming tomfoolery, I stumbled into an
interesting scenario. It occurred to me that with some work, I could
probably turn what I had into a functioning compile-time random
number generator, despite D's restrictions on metaprogramming intended
to keep things deterministic. Some of this may be obvious to you,
some of it may be interesting. Whether or not any of this is a bug, I do
not know. It probably isn't useful unless trying to sabotage a codebase.
Note: This is specifically developed with minimal dependence on other
modules (even standard ones), so some things are implemented in
non-idiomatic (read: strange) ways.
+/
/+
Step 1
We need something useable as a seed. Luckily, D has __TIMESTAMP__, which
reports time of build as a string in roughly the following format:
Wed Jan 20 18:04:41 2016
Specific contents of this function don't matter. All that matters is
timestamp goes in, largish unsigned integers come out. Feel free to skip
the implementation, it is not important. All that matters is that with
this, we will be able to get a psuedo-random seed at compile-time.
We *could* parse the timestamp accurately, but the rest of this is
hackish, so why not make this hackish as well?
+/
ulong timestampToUlong(string stamp)
{
ulong result;
foreach_reverse(c; stamp)
{
result += c;
result *= 10;
}
return result;
}
/+
Step 2
Next, we'll need the ability to track some sort of state. D is designed
with the intention that compile-time constructs cannot have a useful
permanent state, so this'll take some doing.
For starters, we need something we can query that can give different
results different times we call it (as in, impure). For this, we
have the following templated enum. It is manifest constant giving
the number of top-level members in the current module. However,
this number can change as other templates and mixins are resolved.
Technically, each instantiation is different, but because the dirty
details are hidden inside the default parameter value, it can be used
as if it should always be the same value.
+/
enum counter(size_t x = [__traits(allMembers, mixin(__MODULE__))].length)=x;
/+
Step 3
For step 2 to work, we also need the ability to add members in between
uses of `counter`. These need to be uniquely named, so we will
need a way to generate names. Step 2 already gave us a source of
increasing numbers, so we can trivially generate names based on
the value of `counter`. So, we define a method to yeild a string
containing a new unique declaration that we can `mixin()`.
+/
char[] member(ulong x)
{
char[] buf = "void[0] _X0000000000000000;".dup;
enum mapping = "0123456789abcdef";
foreach_reverse(i; buf.length-17 .. buf.length-1)
{
buf[i] = mapping[x & 0xf];
x >>= 4;
}
return buf;
}
/+
Step 4
This is just a simple wrapper combining `member` and `counter` under
a single name, making it slightly easier to increment the counter.
+/
mixin template next()
{
mixin(member(counter!()));
}
/+
Step 5
Finally, we define a simple XorShift64* RNG. We don't really
have arbitrary mutable state (yet?), so this depends on the D
compiler caching previous template instantiations.
The first is a specialization introducing our seed.
The second is how all subsequent xorShift instantiations are
handled, again taking advantage of changing default parameters.
+/
template xorShift(size_t x = counter!())
{
static if(x == 0)
{
enum xorShift = timestampToUlong(__TIMESTAMP__);
}
else
{
// Name previous result to reduce syntax noise.
enum y = xorShift!(x-1);
enum xorShift = 0x2545_f491_4f6c_dd1dUL
* (((y ^ (y >> 12)) ^ ((y ^ (y >> 12)) << 25))
^ (((y ^ (y >> 12)) ^ ((y ^ (y >> 12)) << 25)) >> 27));
}
}
/+
Now, let's use it!
+/
// Two instantiantions of xorShift result in the same value
static assert(xorShift!() == xorShift!());
// However, we can save one value,
enum a = xorShift!();
// ... update the counter,
mixin next;
// ... and save another value,
enum b = xorShift!();
// ... and they will not be the same.
static assert(a != b);
/+ What's more, because we have a time based seed, they will
all be different every time you compile this code. +/
pragma(msg, a);
pragma(msg, b);
mixin next;
mixin template headsOrTails(size_t x)
{
static if(x % 2 == 0)
{
pragma(msg, "Heads!");
}
else
{
pragma(msg, "Tails!");
}
}
mixin headsOrTails!(xorShift!());
/+
Conclusion
This is a really simple proof of concept. A "better" version
could use a recursively scanning counter implementation that
looked for symbols tagged with a certain User-Defined attribute
to allow advancing the RNG state inside structs and such.
More complicated RNGs could be implemented in a similar way.
There may be value in mixing in template specializations.
But then again, all this code is evil and I won't be doing
anything more with it.
+/
void main()
{
// Don't do anything at runtime. Just make dpaste's linker happy.
}
While the D phenomenon relies primarily on benevolent effort, a bit of money can go a long way towards enhancing documentation, supporting libraries, compilers and IDEs.
If your company depends on a healthy D ecosystem, your donations will have a noticeable impact in spreading D to the programming world, while hedging against related technology risks.
The D Language Foundation is a 501(c) non-profit public charity devoted to advancing open source technology related to the D programming language.
A one-stop shop for pushing the interests of the D world at large.
You can contribute for free through Amazon Smile! https://forum.dlang.org/thread/pikn41$u9q$1@digitalmars.com
The LDC project is pivotal to many D companies that profit from top performance.
If you are one of them, consider giving back to this critical piece of infrastructure...
The GDC project is also pivotal to high-performance D. As part of GCC, GDC is the D compiler with the most platform reach, so funding GDC is a great technology hedge.
Adam D. Ruppe is the creator of http://dpldocs.info/ (online and fast documentation for any DUB package) and author of D Cookbook. https://www.patreon.com/adamdruppe/overview
Basile B creates Coedit, an IDE specially purposed for D (donation link on the Github page).
WebFreak creates code-d a Visual Studio Code extension for dlang: https://www.patreon.com/WebFreak/overview
Let us know if you identify other ecosystem contributors with a donation link!
Use std.string.toStringz.
extern(C) nothrow @nogc void log_message(const char* message);
void logMessage(string msg)
{
import std.string: toStringz;
log_message(toStringz(msg));
}
D string literals are already zero-terminated, you don't have anything to do in this case.
extern(C) nothrow @nogc void window_set_title(const char* title);
void main()
{
window_set_title("Welcome to zombo.com"); // Works: literals terminated with '\0'
}
See also: http://dlang.org/phobos/std_string.html#.toStringz
Use std.string.fromStringz.
extern(C) nothrow @nogc char* window_get_title(window_id id);
struct Window
{
// Note: to avoid allocations you can return a slice within the C string
// and keep the slice constant. Else you can use .dup or .idup to get
// an immutable string.
const(char)[] name(string msg)
{
import std.string: fromStringz;
return fromStringz( window_get_title(_id) );
}
window_id _id;
}
What if you already know the length of the C string?
Then you can use regular slicing.
assert(len == strlen(messageC));
string messageD = messageC[0..len];
See also: http://dlang.org/phobos/std_string.html#.fromStringz
format() for builtin typesWhen using std.conv.to() or std.stdio.write(), the arguments are formatted using a predefined format.
Structs are processed differently. By default, all the members of a struct are converted
but the internal to() also checks if a struct implements a custom toString() function.
If so, this function is used and the default formatting of the members doesn't happen.
This can be used as a trick to override the default predefined formats of a basic type.
For example, to display a pointer as a hexadecimal address prefixed with 0x, we can define a struct with a single member of type void* and a custom toString() function:
import std.stdio;
struct FmtPtr
{
void* ptr;
string toString()
{
import std.format;
static if (size_t.sizeof == 4)
return format("0x%.8X ", cast(size_t)ptr);
static if (size_t.sizeof == 8)
return format("0x%.16X ", cast(size_t)ptr);
}
}
void main(string[] args)
{
import core.stdc.stdlib;
auto a = malloc(8);
auto b = malloc(8);
auto c = malloc(8);
// ugly custom formatting
writeln("0X", a, " ", "0X", b, " ", "0X", c);
writefln("0X%.8X 0X%.8X 0X%.8X", a, b, c);
// clean and clear equivalent using the struct
writeln(FmtPtr(a), FmtPtr(b), FmtPtr(c));
}
Coined and promoted by Andrei Alexandrescu, Design by Introspection (also known as "DbI") means something pretty specific: instead of multiplying the number of named concepts in generic code, let's inspect types at compile-time for capabilities.
An example is Phobos' input ranges that can be infinite regardless of the particular compile-time concept they follow.
In the D language, such duck-typing at compile-time seems to unlock most interesting designs.
std.range.primitives: http://dlang.org/phobos/stdrangeprimitives.html
std.experimental.allocator: http://dlang.org/phobos/stdexperimentalallocator.html
There is currently not much written on this programming technique.
The best resource on the topic is probably this talk by Alexandrescu: std::allocator Is to Allocation what std::vector is to Vexation.
By and large D integer handling is identical to C. However there are some differences you might want to be aware of.
By design, none of those can break C code ported to D.
>>> operatorD has a >>> operator to force unsigned right bit-shifting, regardless of the type of the left operand.
import std.stdio;
void main()
{
short i = -48;
writeln(i >> 1); // Output: -24
// unsigned shift, regardless of signedness of i
writeln(i >>> 1); // Output: 2147483624
writeln(typeof(i >>> 1).stringof); // Output: int
}
The >>> operator promotes integers like the other bit-shifting operators.
In D signed integer overflow is well-defined with wrapping semantics. You can rely on it and don't have to avoid signed overflow.
Source: https://forum.dlang.org/post/n23bo3$qe$1@digitalmars.com
The current agreement on best practices with regards to @property is to not use it.
@property does very little and you can always avoid it.
__DATA__Using import(__FILE__) allows to embed data at the end of a D file.
Here is an example from the D newsgroups:
#! /usr/bin/env dub
/++ dub.sdl:
dependency "dxml" version="0.4.0"
stringImportPaths "."
+/
import dxml.parser;
import std;
enum text = import(__FILE__)
.splitLines
.find("__EOF__")
.drop(1)
.join("\n");
void main() {
foreach (entity; parseXML!simpleXML(text)) {
if (entity.type == EntityType.text)
writeln(entity.text.strip);
}
}
__EOF__
<!-- comment -->
<root>
<foo>some text<whatever/></foo>
<bar/>
<baz></baz>
more text
</root>
See also: D lexer special tokens.
Slice indexing will check bounds depending on -boundscheck and @safe.
But pointer indexing won't ever check bounds.
int[] myArray;
myArray.ptr[index] = 4; // no bounds check, guaranteed
__traits(allMembers) and "static" foreachUsing __traits(allMembers, X) allows us to iterate on the fields of a struct or class.
This can be useful when:
.dup, copy, … for any aggregate
Here's how DUB implements a .dup with __traits(allMembers):
BuildSettings dup() const
{
BuildSettings ret;
// Important: this foreach is a special "static" foreach
// though it isn't visually different from a regular foreach
foreach (m; __traits(allMembers, BuildSettings))
{
static if (is(typeof(__traits(getMember, ret, m) = __traits(getMember, this, m).dup)))
__traits(getMember, ret, m) = __traits(getMember, this, m).dup;
else static if (is(typeof(__traits(getMember, ret, m) = __traits(getMember, this, m))))
__traits(getMember, ret, m) = __traits(getMember, this, m);
}
return ret;
}
When new members are added to BuildSettings, this generic .dup will still duplicate them.
The term eponymous templates refers to a symbol with the same name as its enclosing template block.
template HasUniqueElements(int[] arr)
{
import std.algorithm : sort, uniq;
import std.array : array;
enum bool HasUniqueElements = arr.sort().uniq.array.length == arr.length;
}
static assert(HasUniqueElements!( [5, 2, 4] ));
static assert(!HasUniqueElements!( [1, 2, 3, 2] ));
In symbol resolution, the template instantiation is replaced by the enclosed declaration with the same name. In a way, this is like alias this, but for templates.
Bill Baxter came up with the eponymous name in this thread.
struct constructionstruct MyStruct
{
this(int dummy)
{
}
}
// This is explicit constructor call
MyStruct a = MyStruct(0);
// This is an implicit constructor call
MyStruct b = 1;
// Blit, and eventually postblit call if it is defined
MyStruct c = b;
// Same as previous line, parameters created from existing structs
myFunction(c);
// Implicit call to `opAssign` with an `int` parameter, fails if it doesn't exist
a = 2;
// Implicit call to default opAssign, or a custom one with a `MyStruct` parameter
b = a;
// Same as previous line
// Except a temporary instance is created and destroyed on that line
c = MyStruct(3);
struct MyAggregateStruct
{
// `MyStruct(0)` evaluated at CTFE,
// not during MyAggregateStruct construction!
MyStruct a = MyStruct(0);
}
Struct declarations are the one place in D where implicit construction can happen.
Postblits only happen when a new struct is created from an existing one. If the destination already exists it's a regular opAssign call instead.
To avoid unnecessary copy-construction, either @disable the post-blit or pass such a struct by reference.
When an aggregate is created, its members don't get constructed but default initialized with .init. Default values for members gets evaluated using CTFE, and stuffed into .init.
alias thisWhat if we want to decorate a struct with additional features?
We can't use virtual dispatch since the parent aggregate is a struct.
That means we are on board for extensive manual delegation of method calls to a member.
Fortunately the alias this feature comes to the rescue!
As an example, let's write a wrapper around the Phobos File struct for writing an HTML page.
import std.stdio;
import std.file;
struct HTMLPage
{
File file;
alias file this; // file's methods are looked at on name lookup.
this(string path)
{
file = File(path, "w"); // akin to calling parent constructor
}
void writeAnchor(string anchor)
{
writeln("<" ~ anchor ~ ">"); // will call file.writeln
}
}
When using HTMLPage you will still have access to every method in File. For example, you'll be able to do:
htmlPage.writeln("<doctype html>");
This site uses this idiom.
alias this can also define an implicit conversion.
struct A
{
int a;
}
struct B
{
A a;
alias a this;
string b;
}
int f(A a)
{
return a.a+1;
}
int g(ref A a)
{
return a.a+1;
}
ref A h(ref A a)
{
return a;
}
void main(string[]ags)
{
B b;
return f(b) // b implicitely converted to an A
+ g(b); // b implicitely converted to a ref A
}
As TDPL says it, using alias this is subtyping.
In an if(expr) condition, expr does not need to have boolean type.
Falsey value in D are:
null pointer / null delegate / null class reference
false
.ptr data pointer (length of slice is irrelevant)
Thus, the empty string "" points to a single \0 char (string literals are zero-terminated for C compatibility reasons), and is truthy despite having length 0.
ubyte* p = cast(ubyte*)("".ptr);
assert(p != null);
assert(*p == 0);
The static keyword is heavily re-used in the D language. With this uniquely detailed article, you'll learn to recognize the different species of static in the wild.
static member functions and static data membersMuch like in Java and C++, you can declare static data and functions members in a struct or a class. The one caveat is that static data members will be put in Thread Local Storage unless marked with __gshared.
class MyClass
{
// A static member variable => only one exist for all MyClass instances
// You need __gshared here else instanceCount would be thread-local
static __gshared int instanceCount = 0;
// A static member function => does not receive "this"
static void incrementCount()
{
// Can't use "this" here
instanceCount += 1;
}
}
void main()
{
import std.stdio;
MyClass.incrementCount();
writeln(MyClass.instanceCount); // Prints: "1"
}
Additionally, static immutable can be used instead of enum to force compile-time evaluation of a constant, while keeping an address.
This is especially useful for arrays computed at compile-time.
static variables and functionsThis is perhaps the strangest static abuse. At top-level, static does nothing for variables and function declarations.
Here, a TLS (Thread Local Storage) variable:
// At top-level
static int numEngines = 4; // Accepted. Does nothing.
This is 100% equivalent to:
// At top-level.
int numEngines = 4; // The normal way to declare a TLS variable.
Similarly for top-level functions:
static int add(int a, int b) // You can leave out "static" at top-level. It does nothing.
{
return a + b;
}
As the D specification says:
"Static does not have the additional C meaning of being local to a file. Use the private attribute in D to achieve that."
Leave your C++ knowledge about static inline functions and static top-level variables at the door: it doesn't apply here.
static struct, nested static class, and nested static functionsstatic can be put before nested struct, class or functions.
It means "I don't have a pointer to the outer context".
import std.stdio;
void main()
{
float contextData;
struct InternalA
{
void uglyStuff()
{
// can access contextData here, and use this.outer
}
}
static struct InternalB
{
void uglyStuff()
{
// cannot access contextData here, cannot use this.outer
}
}
void subFunA()
{
// can access contextData here
}
static void subFunB()
{
// cannot access contextData here
}
writeln(typeof(&subFunA).stringof); // Prints: "void delegate()"
writeln(typeof(&subFunB).stringof); // Prints: "void function()"
}
To sum up, a nested static struct or static class:
this.outer property,
this.outer is a hidden field.
A nested static function:
function pointer instead of a delegate for this reason.
Arguably the most important static use out of the four we've listed.
static this():Called when a thread is registered to the D runtime. Typically used to initialize TLS variables.
static ~this():Called when a thread is unregistered to the D runtime. Typically used to finalize TLS variables.
shared static this():Called when the D runtime is initialized. Typically used to initialize shared or __gshared variables, for example in Derelict.
shared static ~this():Called when the D runtime is finalized. Typically used to finalize shared or __gshared variables.
Important: global constructors and global destructors can be placed within a struct or a class, where they will be able to initialize shared, __gshared or static members.
Beware: It's a common mistake to write static this() instead of shared static this(). Don't be a TLS victim.
By default D structs are copyable and that copy is just a .dup verbatim bit copy.
Indeed the default struct postblit does nothing.
struct MyStruct
{
int field;
}
MyStruct a;
MyStruct b;
a = b; // Bit copy here.
The trouble happens with structs that hold a resource: whenever copied, the struct destructor would be called twice, and twice the resource would be freed.
That doesn't look like the beginning of a success story. To solve this, follow the Rule of Two.
If a struct has a non-trivial destructor, then:
- either disable the default postblit with @disable this(this),
- or implement the postblit.
Don't let the default one.
struct MyResource
{
this()
{
acquireResource();
}
~this()
{
releaseResource();
}
// Disabling the postblit to avoid the destructor being
// called twice after an accidental copy.
@disable this(this);
/*
// Alternatively, duplicate the resource
this(this)
{
duplicateResource();
}
*/
}
Quantum Break is an AAA video game developed by Remedy Entertainment (2016).
Is it written in C++ with D as the scripting language. Available on Xbox One and Windows.
See:
Mayhem Intergalactic is the first ever commercial video game written in D (2007).
Available for Windows.
See the newsgroup announcement.
Kenta Cho released a number of Windows shooter games in early D.
Atrium is an unfinished first-person game with physics based puzzles, entirely written with the D programming language.
Vibrant is an arena shooter based on 2D dogfighting. Available for Windows and OS X on Steam.
Jan Jurzitza wrote several Ludum Dare entries.
Class destructors have painful limitations when called by the GC.
But there is a way to make a class holding a resource that:
std.typecons.RefCounted, std.typecons.Unique, std.typecons.Scoped)
object.destroy)
The general idea behind the GC-proof resource class is to check why the destructor was called and act accordingly.
class MyGCProofResource
{
void* handle;
this()
{
// acquire resource
handle = create_handle();
}
~this()
{
// Important bit.
// Here we verify that the GC isn't responsible
// for releasing the resource, which is dangerous.
import core.memory;
assert(!GC.inFinalizer, "Error: clean-up of MyGCProofResource incorrectly" ~
" depends on destructors called by the GC");
// release resource
free_handle(handle);
}
}
You'll get a clear message whenever you rely on the GC to release resources.
This idiom was first introduced in the GFM library.
Surprisingly, there is no __traits or std.traits to do this, but you can use this secret is() syntax to get the parent class of a class.
class A { }
class B : A {}
template ParentOf(Class)
{
static if(is(Class Parents == super) && Parents.length)
alias ParentOf = Parents[0];
else
static assert(0, "No parent for this");
}
static assert(is(ParentOf!B == A));
How to get a class method callbacked from C?
What is needed is a way to pass the this pointer. Most C callbacks allow to specify a "user data" pointer.
A common trick is to cast this into a void* pointer back and forth, and use it as user data.
Here is an example with SDL2 logging handler:
class MyGame
{
this()
{
// Pass this as user data, since most C callbacks have one.
SDL_LogSetOutputFunction(&loggingCallbackSDL, cast(void*)this);
}
// We'd like this method to get called whenever the SDL callback triggers
void onMessage(const(char)* message)
{
// do stuff
}
}
extern(C) // would be extern(System) depending on the library
void loggingCallbackSDL(void* userData, int category, SDL_LogPriority priority, const(char)* message)
{
// Get back the object reference here
MyGame game = cast(MyGame)userData;
game.onMessage(message);
}
package.d is a special filename which is used in import resolution. When reading:
import mymodule;
a D compiler will search for either mymodule.d or mymodule/package.d (and if both exist, it will complain about the name conflict).
This feature allows to organize modules logically and combined with public import to split big modules in several parts.
Here is an example:
// In file path/mypackage/package.d
module mypackage;
public import mypackage.foo;
public import mypackage.bar;
// In file path/mypackage/foo.d
module mypackage.foo;
// In file path/mypackage/bar.d
module mypackage.bar;
// In user code
// mypackage.foo and mypackage.bar are also imported
import mypackage;
Warning: this post is opinionated.
With C++ evolving and coming to C++17, is D still relevant?
I think that yes, and very much so. Here's is why.
D has a package manager. C++ has none that is popular in its community.
Using a third-party library becomes many times easier.
D has no need for a preprocessor.
Even when C++ compilers implement modules and you can finally use them, headers will still survive alongside modules for backward compatibility.
Order of declaration is insignificant in D. There is no need to pre-declare or reorder anything.
C++ has compilation speed problems. For example the preprocessor needs to iterate on source files at least 3 times by design.
In C++ development, significant amounts of time can be spent waiting for the compiler.
Uninitialized variables can create subtle and hard to find bugs in C++ programs. In D all variables and members are initialized by default. If that happens to be expensive, the = void initialization can be used instead.
A name conflict when importing modules with the same identifier triggers a compilation error. It is thus impossible to use the wrong symbol by mistake.
This is a long-standing problem with C and C++.
Ranges provides a number of advantages over iterators, being essentially a better tool for iteration.
D makes the assumption that structs and classes are copyable by bit copy. It adds some restrictions on internal pointers, but overall it's simpler.
unittest blocksBuilt-in unit-tests lower the barrier for testing.
Similarly built-in documentation comments lower the barrier for writing documentation comments.
Reading Phobos source code is easy and often enlightening.
C++ having multiple inheritance implies a complex object model.
With alias this, multiple implementation inheritance is pretty much never needed.
Making custom numerical types requires a lot less operator overloads.
See how here.
For the large majority of programs, the GC is a productivity enhancer. For the other programs, it's not that bad and can be work-arounded.
The easier and more powerful templates of D allow any programmer to create meta-programs routinely. Not just one programmer in your team which happen to be comfortable with them.
Learning to use D well is tricky, but you can use a subset from the get-go.
For balance, here are the downsides (opinionated again):
There seems to be a stigma surrounding Garbage Collection when you talk to C++ users. The GC would be an wild memory-hungry beast that can't be tamed, essentially outside the control of the programmer. It would render real-time work impossible by its mere presence.
But the D Garbage Collector is firmly under the application control. Once you learn how it works, it doesn't seem so uncontrollable, and reveal itself as what it really is: a trade-off that most modern languages have choosen.
First of all, collections are not triggered randomly but when a thread allocates memory.
Intuitively, one can see that memory scanning is a potentially long and expensive process. Keeping a small GC heap makes it faster.
What you can do to accelerate scanning is using malloc/free instead of new to allocate big chunks of memory.
Anything that reduces the total amount of GC-owned memory will reduce the maximum pause duration.
if (__ctfe)D will run a lot of things through Compile-Time Function Execution (CTFE) if you ask for it.
Sometimes it is useful to branch based on whether the function is executing at compile-time or runtime.
That's what __ctfe is for.
import std.stdio;
string AmIInCTFE()
{
if (__ctfe)
return "Hello from CTFE!";
else
return "Hello from runtime!";
}
void main(string[] args)
{
writefln(AmIInCTFE());
pragma(msg, AmIInCTFE());
}
if embedded declarationIt's legal to declare a variable inside an if condition.
// AA lookup shortcut
if (auto found = key in AA)
{
// found only defined in this scope
doStuff(*found);
}
The branch is taken if the right expression evaluates to a truthy value.
// Equivalent for Java's instanceof
if (auto derived = cast(Derived)obj)
{
// derived only defined in this scope
doStuff(derived);
}
D officially forbid implicit conversions for user-defined types to avoid the pitfalls associated with them.
But defining an implicit conversion is actually possible by abusing alias this.
import std.stdio;
struct NumberAsString
{
private string value;
this(string value)
{
this.value = value;
}
int convHelper()
{
return to!int(value);
}
alias convHelper this;
}
void main(string[] args)
{
auto a = NumberAsString("123");
int b = a; // implicit conversion happening here
writefln("%d", b);
}
This idiom was discovered by Benjamin Thaut.
When in doubt, do it like Phobos!
class MyOwnException : Exception
{
public
{
@safe pure nothrow this(string message,
string file =__FILE__,
size_t line = __LINE__,
Throwable next = null)
{
super(message, file, line, next);
}
}
}
This functions checks the PATH environment variable, looking for a specific program.
// Similar to unix tool "which", that shows the full path of an executable
string which(string executableName)
{
import std.process: environment;
import std.path: pathSeparator, buildPath;
import std.file: exists;
import std.algorithm: splitter;
// pathSeparator: Windows uses ";" separator, POSIX uses ":"
foreach (dir; splitter(environment["PATH"], pathSeparator))
{
auto path = buildPath(dir, executableName);
if (exists(path))
return path;
}
throw Exception("Couldn't find " ~ executableName);
}
If the command isn't available, this function will throw an Exception.
which("wget").writeln; // output: /usr/bin/wget
It is common in Design by Introspection to decide between a runtime value and a compile-time value.
For example, our generic example library will operate on a Volcano concept.
The only requirement is to have a .magma property, be it compile-time or runtime, implicitely convertible to int.
template isVolcano(S)
{
enum bool isVolcano = hasMagma!S; // only requirement for now
}
template hasMagma(S)
{
enum bool hasMagma = is(typeof(
()
{
S s = S.init;
int d = s.magma; // need a magma property
}));
}
It turns out generic algorithms can work with both a runtime or compile-time .magma property, with this simple C++ trick.
template hasStaticMagma(S)
{
enum bool hasStaticMagma = hasMagma!S && __traits(compiles, int[S.magma]);
}
void myVolcanoGenericAlgorithm(S) if (isVolcano!S)
{
static if (hasStaticMagma!S)
{
// optimized version for statically known .magma ...
}
else
{
// plain version ...
}
}
You aren't forced to choose runtime or static for your meta-programming design. This idiom enables faster code when some value is statically known, without necessarily hindering your design.
inout inside outinout is a good-looking storage class. When should it be used?
inout is great for writing getters returning references.struct MyBuffer(T)
{
private T* data;
// This getter needs inout to fit MyBuffer,
// const(MyBuffer) or immutable(MyBuffer) as caller
inout(T)* getData() inout // <= 2nd inout applies to "this"
{
return data;
}
}
It avoids to write the longer equivalent:
// Longer struct without inout
struct MyBuffer(T)
{
private T* data;
T* getData()
{
return data;
}
const(T)* getData() const
{
return data;
}
immutable(T)* getData() immutable
{
return data;
}
}
inout is also useful for free functions walking reference types:// An example of a useful free function using inout
inout(char)[] chomp(inout(char)[] str)
{
if (str.length && str[$-1] == '\n')
return str[0..$-1];
else
return str;
}
inout variables inside of an inout-enabled function:// Useless example to demonstrate inout local variables
inout(int)[] lastItems(inout(int)[] arr, size_t pivot)
{
// Local inout variables are allowed
inout(int)[] lasts = arr[nth+1..$];
return lasts;
}
But inout member variables are not allowed, because inout doesn't mean anything outside the context of a function.
struct InoutMember
{
inout(int) member; // Wrong, won't compile
}
In D the declarations you reasonably thought would be globals, are instead put in Thread-Local Storage (TLS) unless marked with shared or __gshared. Each thread the runtime knows has its own independent copy of TLS things.
class A
{
static int instanceCount = 0; // Caution: one per thread
}
TLS is useful to avoid locks when accessing global state.
In this example, we'll show how to leverage TLS to avoid a costly synchronized block and still be thread-safe.
class FastSingleton
{
private:
this()
{
}
// TLS flag, each thread has its own
static bool instantiated_;
// "True" global
__gshared FastSingleton instance_;
public:
static FastSingleton get()
{
// Since every thread has its own instantiated_ variable,
// there is no need for synchronization here.
if (!instantiated_)
{
synchronized (FastSingleton.classinfo)
{
if (!instance_)
{
instance_ = new FastSingleton();
}
instantiated_ = true;
}
}
return instance_;
}
}
This singleton implementation was taken from this talk by David Simcha.
If you find any other use for TLS, please send us your discoveries.
pragma(mangle)pragma(mangle) is extremely useful when you need to statically link with a C function whose name is a reserved D keyword:
pragma(mangle, "version") extern(C) void c_version();
min and max are found in std.algorithm, not std.math.
import std.algorithm : max;
int a = -5;
int b = 4;
double c = 10.0;
double max_abc = max(a, b, c);
assert(max_abc == 10.0);
They work with builtin types and any number of arguments.
See: http://dlang.org/phobos/std_algorithm.html#.min
There is no standard function to get the minimum and maximum element of a slice.
But you can use std.algorithm.reduce().
import std.algorithm : min, max, reduce;
double[] slice = [3.0, 4.0, -2.0];
double minimum = reduce!min(slice);
double maximum = reduce!max(slice);
assert(minimum == -2.0);
assert(maximum == 4.0);
Using DUB and dependencies? Here is a pattern you should avoid:
{
"name": "my-program",
"dependencies":
{
"awesome-lib": ">=1.0.0"
}
}
Depending on a library using >= is risky. If awesome-lib breaks its API then releases a new major tag, your project will break. This is implicit in SemVer and using >= suscribes for immediate breakage.
Now this can be useful for executables, but this is especially bad for publicly released libraries. Any downstream project might break in the future when using your already released tags. And how will you fix tags that are already in use?
TL;DR Do not depend on APIs that will break in the future. Use ~> or == instead.
new for static arraysIt just happens that in D you can't use new to get a pointer to a newly allocated static array.
void main()
{
alias T = int[4];
// This line does not compile!
// Error: new can only create structs, dynamic arrays or class objects, not int[4]'s
auto t = new T;
}
"You can only call new with structs, dynamic arrays, and class objects" says the compiler.
Unrelated: actually the compiler is lying a bit, since it is possible to allocate a single (builtin type) value on the heap:
void main()
{
int* p = new int; // Works
}
But this can't be with static arrays, despite them being value types. Doesn't that sound like an inconsistency? Something that would have to be explained.
The reasoning for new and static arrays was probably that you rarely really want to allocate a static array on the heap; it could just as well be a slice.
So there is no syntax to do this.
When you do write new int[4] this will instead return an int[] slice with a length of 4, which adds the benefits of holding a length.
writeln(typeof(new int[4]).stringof); // output: "int[]"
auto arr = new int[4];
writeln(arr.length); // output: "4"
arr ~= 42;
writeln(arr.length); // output: "5"
So far, so good.
It gets weirder whenever shared, const and immutable get introduced...
If for some reason you really need a static array allocated on the heap instead of a slice, you can do it anyway by using std.experimental.allocator (or its DUB equivalent stdx-allocator):
import std.experimental.allocator;
void main()
{
alias T = int[4];
// T* t = new T; // Won't work.
T* t = theAllocator.make!T; // Fine!
assert((*t).length == 4); // Safe too.
(*t)[1] = 42; // Needs pointer dereference and parentheses before use.
assert(*t == [0, 42, 0, 0]); // Features default initialization.
// (*t) ~= 43; // Error: cannot append type int to type int[4]
}
This idiom got some help from Bastiaan Veelo.
When used on an Associative Array, the in operator returns either a pointer to the searched for element, or null if not found.
Instead of:
key in aa ? aa[key] : ValueType.init;
which perform 2 AA lookups prefer:
auto ptr = key in aa;
ptr ? *ptr : ValueType.init;
The .get builtin property can also be used. It provides a default value when the key doesn't exist.
aa.get(key, defaultValue);
Associative arrays in D are akin to C++'s std::unordered_map, not std::map.
This performs a parallel loop with a default task pool.
import core.atomic;
import std.parallelism;
import std.range;
void main()
{
shared(int) A = 0;
foreach(n; iota(2000).parallel)
{
atomicOp!"+="(A, 1);
}
assert(A == 2000);
}
How to patch a DUB library with minimal hassle for users?
dub add-local or dub test can help to do it.
1.0.0 instead of v1.0.0, else the registry won't take it. Likewise avoid leading zeroes like v2.3.04.
git push then git push --tags but to be honest I don't really know why it's better in this order. At this point the fix is online. This is not finished yet!
Trigger manual update button. This will acknowledge the new version and allow downstream to update to the new tag as soon as possible. Do not skip this step if you want a timely fix. If you don't do the manual update, the new tag will be acknowledged by the registry in less than 30 minutes.
dub clean-caches to update the list of available packages.
Planet D is a blog aggregator much more complete than this list:
http://planet.dsource.org/
There is no shortage of useful and surprising things in the D standard library.
Here is some of the most useful stuff.
std.exception.enforceIt is good practice to check for unrecoverable errors with assert, and recoverable errors with enforce.
Which means you should learn the difference between those two types of errors.
See: http://dlang.org/phobos/std_exception.html#.enforce
object.destroy()Whenever you want to destroy an object manually, destroy() is probably what you want.
As a part of object.d, it is always available.
See: http://dlang.org/phobos/object.html#.destroy
std.typecons.scopedscoped replaces new and put a class object on the stack, with the double benefit of avoiding GC and performing deterministic destruction.
import std.typecons;
auto myClass = scoped!MyClass(); // no need for 'new', and automatic destructor call at scope exit.
See: http://dlang.org/phobos/std_typecons.html#.scoped
std.traits.UnqualUnqual enables to write template and instantiate them with const(T), immutable(T), shared(T)…
See: http://dlang.org/phobos/std_traits.html#.Unqual
std.array.arrayarray is usually used to convert a range computation to a dynamic array.
See: http://dlang.org/phobos/std_array.html#.array
emplaceC++ has "placement new" which is a language construct to construct an object at a given pointer location.
The D equivalent is a Phobos function called std.conv.emplace (documentation here).
emplace can be used as an alternative to new to support custom allocation. For example this perform construction of a class instance on the stack.
import std.conv : emplace;
ubyte[__traits(classInstanceSize, YourClass)] buffer;
YourClass obj = emplace!YourClass(buffer[], ctor args...);
// Destroy the object explicitly at scope exit, which will
// call the destructor deterministically.
scope(exit) .destroy(obj);
Courtesy of Adam D. Ruppe.
__gsharedVariables at global scope are in Thread Local Storage (TLS) unless qualified with shared or __gshared. You are probably wanting to use __gshared.
// A C global variable
int my_global_var;
// Equivalent D global
__gshared int myGlobalVar;
long and unsigned longC's long and unsigned long have variable size, no builtin type is equivalent in D!
The recommended way is to use c_long and c_ulong from module core.stdc.config.
// A C function declaration
unsigned long countBeans(const long *n)
// Equivalent D function declaration
import core.stdc.config;
c_ulong countBeans(const(c_long)* n);
c_int and c_uint also exist to replace int and unsigned int, but because they are 32-bits in most architectures, it's usually simply translated with D's int and uint instead.
charIn C, the char type can refer to either signed char or unsigned char, depending on the implementation.
In D, char is always an unsigned integer (0 to 255). If you need the equivalent of signed char, use byte.
// A C function declaration
unsigned char * computeBlurb(signed char *data);
// Equivalent D function declaration
char* computeBlurb(byte* data);
// A C array declaration
int myMatrix[4][2] = { { 1, 2}, { 3, 4}, { 5, 6}, { 7, 8} };
// Equivalent D array declaration
int[2][4] myMatrix = [ [ 1, 2], [ 3, 4], [ 5, 6], [ 7, 8] ];
// A C enum declaration
typedef enum
{
STRATEGY_RANDOM,
STRATEGY_IMMEDIATE,
STRATEGY_SEARCH
} strategy_t;
// Equivalent D enum declaration
alias strategy_t = int;
enum : strategy_t
{
STRATEGY_RANDOM,
STRATEGY_IMMEDIATE,
STRATEGY_SEARCH
}
This avoids having to write strategy_t.STRATEGY_IMMEDIATE instead of STRATEGY_IMMEDIATE when porting C code.
struct and unionD provides a limited form of anonymous nested struct and union, but they can't be used to translate this C anonymous struct:
// A C anonymous struct
struct Foo
{
struct
{
int x;
} bar;
};
// Equivalent D
struct Foo
{
private struct bar_t
{
int x;
}
bar_t bar;
}
When porting from C, you will probably have to spam .ptr anywhere an array is implicitely converted to a pointer.
// In C
void sum(const int *array, int n);
int coeff[16];
sum(coeff, sizeof(coeff) / sizeof(int));
// In D
void sum(const(int)* array, int n);
int[16] coeff;
sum(coeff.ptr, coeff.sizeof / int.sizeof); // array not implicitely convertible to a pointer
D compilers provide extensive Compile-Time Function Execution.
This feature allows to easily compute almost anything at compile-time, without using an external program.
Here is an example of a precomputed array from the GFM library.
static immutable ushort[64] offsettable =
(){
ushort[64] t;
t[] = 1024; // Fills the table with 1024
t[0] = t[32] = 0;
return t;
}();
What is happening there?
(){ /* body */ } is short syntax for a delegate literal returning auto with no argument.
So, (){ /* body */ }() means that we call that delegate immediately.
the literal is executed at compile-time, as enforced by static immutable.
But why not use enum for this purpose?
For large constants, prefer using static immutable over enum.
It's important that static immutable is used in the previous example instead of just enum. This will create a constant with an address.
enum creates a compile-time only construct.static immutable actually puts it in the static data segment.
// This example highlights the difference between "enum" and "static immutable" for constants.
import std.stdio;
bool amIInCTFE()
{
return __ctfe;
}
void main()
{
bool a = amIInCTFE(); // regular runtime initialization
enum bool b = amIInCTFE(); // forces compile-time evaluation with enum
static immutable bool c = amIInCTFE(); // forces compile-time evaluation with static immutable
writeln(a, " ", &a); // Prints: "false <address of a>"
//writeln(b, " ", &b); // Error: enum declarations have no address
writeln(c, " ", &c); // Prints: "true <address of c>"
}
Using enum would duplicate the constant at each call-site, which is inefficient for arrays and may even lead to allocations on use point in the same way than array literals allocate!
This pre-computed fibonacci example fails to compile:
enum int[] fibTable =
(){
int[] t;
t ~= 1;
t ~= 1;
int precomputedValues = 128;
foreach(i; 2..precomputedValues)
t ~= t[i - 1] + t[i - 2];
return t;
}();
int fibonacci(int n) pure @nogc
{
if (n < fibTable.length) // Error: array literal in @nogc function fibonacci may cause GC allocation
return fibTable[n];
else
return fibonacci(n - 1) + fibonacci(n - 2);
}
For all the other uses of static, read this article.
Let's say we have an enum:
enum MyEnum
{
small,
normal,
huge
}
Switching on an enum value is annoying and redundant: MyEnum has to be repeated for each case.
final switch(enumValue)
{
case MyEnum.small:
writeln("small");
break;
case MyEnum.normal:
writeln("normal");
break;
case MyEnum.huge:
writeln("huge");
break;
}
We can work-around this by using with:
final switch(enumValue) with (MyEnum)
{
case small:
writeln("small");
break;
case normal:
writeln("normal");
break;
case huge:
writeln("huge");
break;
}
This idiom was discovered by Amaury Sechet.
Never write a tagged union by hand again! std.variant.Algebraic solves this nicely.
Recursive data-types are supported despite the documentation saying it's not.
import std.variant, std.typecons;
alias Symbol = Typedef!string;
// an Atom is either:
// - a string,
// - a double,
// - a bool,
// - a Symbol,
// - or Atom[]
alias Atom = Algebraic!(string, double, bool, Symbol, This[]); // Use 'This' for recursive ADT
Atom atom;
if (bool* b = atom.peek!bool()) // is atom a bool?
{
// here *b is a bool
}
Algebraic can be used with the visit function to do an exhaustive match.
// an exhaustive match with this ADT
string toString(Atom atom)
{
return atom.visit!(
(Symbol sym) => cast(string)sym,
(string s) => s,
(double x) => to!string(x),
(bool b) => (b ? "#t" : "#f"),
(Atom[] atoms) => "(" ~ map!toString(atoms).joiner(" ").array.to!string ~ ")"
);
}
It is easy to rename a function or object in D with the deprecated alias idiom.
deprecated("Use myNewFun() instead") alias myOldFun = myNewFun;
void myNewFun()
{
// Show a deprecation message if called with myOldFun() name
}
deprecated can also be used for module renaming.
deprecated("Import lib.newer.mod; instead") module lib.older.mod;
public import lib.newer.mod;
However, at times you might want to write code that can work without deprecation message, with either the new or old module name.
That is also possible:
static if (__traits(compiles, (){import my.renamed.mod;}))
import my.renamed.mod;
else
import my.original.mod;
The origin of that idiom is unknown, but probably first appeared in the arsd library.
auto ref and then not using it"Rvalue references", known from C++, are a way to pass both Lvalues and Rvalues by reference.
It looks like this:
#include <iostream>
struct Vector2f
{
float x, y;
explicit Vector2f(float x, float y) : x(x), y(y)
{
}
};
void foo(const Vector2f& pos)
{
std::cout << pos.x << '|' << pos.y << std::endl;
}
int main()
{
Vector2f v(42, 23);
foo(v); // Pass a Lvalue, works
foo(Vector2f(42, 23)); // Pass a Rvalue, works as well
}
How do you achieve something similar in D?
auto ref parametersThe canonical way to pass both Rvalues and Lvalues in D is to use auto ref parameters in combination with templates.
struct A
{
int id;
}
void test(T)(auto ref T a)
{
}
//
// Case 1:
//
// This generates one function:
//
// void test(ref A a) { ... }
//
// taking the argument by ref.
A a = A(42);
test(a);
//
// Case 2
//
// This generates another function:
//
// void test(A a) { ... }
//
// taking the argument by value.
test(A(42));
What auto ref does is generating two different versions of the function, one passing Lvalues by reference, and the other passing Rvalues by copy.
Wait! You may immediately notice two key differences with C++:
auto ref may lead to template bloat with many such parameters.
You'll be relieved to know there is a way to mimic the C++ behaviour.
Let's define in our struct a byRef method which return this by reference.
import std.stdio;
mixin template RvalueRef()
{
alias T = typeof(this); // typeof(this) get us the type we're in
static assert (is(T == struct));
@nogc @safe
ref const(T) byRef() const pure nothrow return
{
return this;
}
}
struct Vector2f
{
float x, y;
this(float x, float y) pure nothrow
{
this.x = x;
this.y = y;
}
mixin RvalueRef;
}
void foo(ref const Vector2f pos)
{
writefln("(%.2f|%.2f)", pos.x, pos.y);
}
void main()
{
Vector2f v = Vector2f(42, 23);
foo(v); // Works
foo(Vector2f(42, 23).byRef); // Works as well, and use the same function
}
By effectively converting the Lvalue into an Rvalue using the ref storage class on a function return type, we can pass the Vector2f to a function taking ref const input.
This idiom was written by Randy Schütt.
The indexOf function in std.string gives back the index of the first found substring or -1 if missing.
import std.string;
assert(indexOf("Hello home sweet home", "home") == 6);
Either one. It did matter a bit in C++ but doesn't in D. The compiler rewrites internally post-increments to pre-increments if the expression result is unused.
it++; // lowered to ++it since the result isn't used
it--; // ditto, lowered to --it
Contrarily to C++, a single operator overload is used to define both pre-increment and post-increment in user-defined types.
struct WrappedInt
{
int m;
// overload both ++pre and post++
int opUnary(string op)() if (op == "++")
{
return ++m;
}
}
= voidIn D, everything is initialized by default.
Because it may have a runtime cost, the syntax = void allows to skip default assignment for stack variables.
void bark()
{
int dog = void; // dog contains garbage
if(cond)
dog = 1;
else
dog = 2;
}
= void is also accepted for struct or class members but doesn't do anything useful at the moment. Don't use it there.
.capacity, the mysterious propertyDynamic arrays aka slices in D have a .capacity property: the maximum length the slice can reach before needing reallocation.
int[] arr = new int[10];
writeln(arr.capacity);
assert(arr.capacity >= arr.length);
Since .capacity is read-only, the .reserve builtin property also exist to ensure allocation size. This is similar to C++'s std::vector::capacity() and std::vector::reserve(size_t n). Handy!
T[] arr;
arr.reserve(N);
foreach(i ; 0..N)
arr ~= expr(i); // guaranteed not to allocate in the loop
I hear you saying: "How is that possible since D slices are only a pointer and a length?"
There is a trick, getting that information relies on the GC, and slices pointing to non-GC memory will report a capacity of 0 which means reallocating is mandatory for appending.
char[16] hexChars = "0123456789abcdef";
char[] decChars = hexChars[0..10];
writeln(decChars.capacity); // output '0' since decChars points to non-GC memory
decChars = decChars.dup; // makes a GC copy of the slice
writeln(decChars.capacity); // outputs non-zero value now that decChars points to GC memory
There is a tendency to call slices that own their memory "Dynamic Arrays" and the ones that don't "Slices"; perhaps to map other languages to D.
This is a harmful dichotomy. That a slice own or not its memory is purely derived from the pointed area.
What DUB options are strictly necessary in a dub.json file to build an executable?
It turns out only one is needed:
{
"name": "program_name"
}
Place the source code in a source/main.d or source/app.d file and DUB will find it and guess
you want to build an executable.
No main.d or app.d? DUB will guess it's a source library then.
There is sometimes a perception in Internet forums that D is a mere repackaging of C++. D would bring more or less the same feature set with a more friendly syntax, and not bring any new possibility.
The goal of this article is to provide counterpoints to this belief. D does allows some design that the community regards as new, alongside with the expected incremental improvements.
Here is an edited list of things that D can do, and C++ can't.
Can this module be imported?
Is this method const?
What is the list of all child classes of the given class?
Branded under the moniker Design by Introspection, static introspection applied to APIs enables code that abandon more type-safety in the quest for more genericity.
Examples:
Compile-Time Function Evaluation, patiently evolved from a "glorified constant folder", is ubiquitous in D. Endlessly applicable, it also requires very few explanations: just add enum and you get it.
Regular looking code, evaluated at compile-time, with only a few limitations: what's not to love?
Examples:
CTFE and deep type introspection would be nothing without the ability to generate code at compile-time easily.
String mixins, templates, mixin templates, "static" foreach are different way in which this can be achieved.
Examples:
The combination of Static Introspection, generative features and CTFE forms the trinity that powers D's unique selling point. It's the fire behind the proverbial smoke.
Module declarations are the things found at the top of modules.
module fancylib.interfaces; // this is a module declaration aka module directive
They seem simple enough, but elicit a number of questions in the long run:
What if we don't name them after their position in the file system?
What if we omit module declarations like some D programs do?
Every module has a module name whether it has a module declaration or not.
If you don't use one, the compiler uses the file name by default, but only the file name. The path on the file system is in no way taken into account.
Given a source file source/foo.d, using the following declaration is the same as not using a module declaration at all:
module foo; // can be omitted for a file source/foo.d
However, you rarely want to omit module declarations, we'll see why.
importWhen a module is imported, the compiler will search for it in D files directly given through the command-line. If this fails, it will append the module name to import directories (the paths given with -I) in order to find such a file.
// Do I know such a module with this name?
// Can I find it in <import-paths>/mylib/foo/bar.d otherwise?
import mylib.foo.bar;
Modules have two ways to be found:
module declaration, as long as such names are used consistently.
-I.
Unless your program is small and self-contained, you should prefer the latter, and use module names matching file pathes in the file-system.
See also: https://dlang.org/spec/module.html#module_declaration
-debug do, exactly?In D compilers, the -debug switch does only one thing: compiling in code in debug clauses.
debug
{
writeln("-debug was used");
}
else
{
writeln("-debug was NOT used");
}
The -debug switch has nothing to do with debug information (-g) of lack thereof.
The -debug switch has nothing to do with optimizations (-O) or lack thereof.
The -debug switch has nothing to do with the -release switch, in fact both switches can be used at once, or none.
There is no "debug mode" or "release mode" in D compilers, those are a DUB convention.
debug identifiers: who are they and what do they want?You can define a "debug identifier" ident that will be compiled in if -debug=ident is passed through the command-line.
debug(complicatedAlg)
writeln("-debug=complicatedAlg was used"); // useful for debug logging
else
writeln("-debug=complicatedAlg was NOT used");
That makes debug remarkedly similar to... version.
debug is indeed strikingly similar to versionThe 2 key differences between -debug and -version are:
Semantic: version is for software features, and debug is to enable logging/information/statistics... about programs with no user-facing effect.
Quick printf-debugging: under a debug clause, you don't have to follow pure, nothrow, @nogc or @safe. It's a special case in the compiler to enable debug logging.
Breaking pure/@nogc/nothrow/@safe with -debug is Undefined Behaviour, though in most cases it will work just fine and you don't have to worry. Just don't ship code with -debug enabled.
Read more about -debug: https://dlang.org/dmd-windows.html#switch-debug
-release do, exactly?In D compilers, the -release switch does the following things:
in and out blocks).
@safe code. That means: @trusted, @system, and unmarked functions won't have bounds checks. To overide this behaviour, use the -boundscheck switch.
assert(false) which is special.See: http://dlang.org/dmd-windows.html#switch-release
TRIVIA: Regardless of the use of -release, assertions are always on whenever the -unittest flag is passed to the compiler. This is the sort of special case that breathes life in this very page!
(Note: on this whole website, with "static arrays" we mean fixed-size arrays, not arrays declared with static).
It's important to note that D static arrays are value types.
void addFour(int[16] arr)
{
arr[] += 4; // Only the local version is modified.
}
void main()
{
int[16] a;
addFour(a); // a is passed by value on the stack, not by pointer.
assert(a[0] == 0);
}
That makes such declaration a trap when porting functions from C or C++.
To pass static arrays by reference, either write a function taking a slice or use ref.
void addFive(ref int[16] arr)
{
arr[] += 5; // Caller parameter modified.
}
void addSix(int[] arr)
{
arr[] += 6; // Caller parameter modified.
}
void main()
{
int[16] a;
addFive(a); // Works, a is passed by reference
addSix(a); // Works, a is converted into a slice referencing the same data
}
One of the oddities about static arrays is that you can't new them.
D doesn't have string interpolation built in the language like PHP, Perl or Python.
Yet you can get a similar feature using the scriptlike library from Nick Sabalausky.
import scriptlike;
int num = 21;
writeln( mixin(interp!"The number ${num} doubled is ${num * 2}.") ); // Output: The number 21 doubled is 42.
interp difficult to implement?It turns out interp is a pretty simple function, forced to execute at compile-time through CTFE by the use of mixin.
scriptlike also provides many more useful features for quick programs.
Homepage: https://github.com/Abscissa/scriptlike
purepure is a good looking function attribute that unfortunately doesn't seem to provide much value at first sight. On the other hand, who doesn't want to write pure code?
How can we justify the horizontal space investment in pure annotations?
The compiler has to assume a non-pure function could modify any global state:
Let's say we have a function lacking a pure annotation.
extern(C) int impureFibonacci(int n);
This function gets called.
int result = impureFibonacci(8);
// Any global state could have changed, like allocated heap, global variables, and so on.
// That's like a barrier for the optimizer.
The compiler must assume any global state could have changed.
pure is documentationAs dreadful as annotation streaks like pure const nothrow @nogc can be, they are some kind of compiler-enforced documentation.
Purity in D by David Nadlinger.
This article was written with the help of Amaury Sechet.
It is often said on Internet forums that D couldn't possibly do real-time work, since its stop-the-world GC might pause every thread at once.
This is wildly inaccurate. The GC pauses all threads registered to the D runtime.
Real-time threads like audio callbacks are doable since forever. Here is how:
Use a thread that isn't registered. Such a thread could be created by an external library, or with core.thread.Thread and then unregistered with thread_detachThis(). This moves the thread out of druntime supervision: it won't be stopped by the GC, and won't be able to use GC allocations.
Make the thread function or callback @nogc. This will enforce you don't use the GC.
Another limitation: Such a thread must not hold roots to GC objects. What it means is that you can use GC objects from the real-time thread, but these GC objects should be pointed to by registered threads to avoid them being collected.
Despite having a GC, resource management in D is one of the most difficult point of the language.
In particular, class destructors in D enjoy a variety of limitations you should be aware of.
The garbage collector is not guaranteed to run the destructors for all unreferenced objects.
Class destructors might be called when a collect is performed which can be later than you wished and by any thread the GC is currently running on.
The order in which the garbage collector calls destructors for unreferenced objects is not specified. Don't use members in class destructors if you expect to be called by the GC.
Using GC allocation is forbidden within a class destructor.
If a class constructor throw, the corresponding destructor will be called as part of the normal teardown sequence! Be prepared for this: your class destructor should check for object validity.
All this is in sharp contrast with the deterministic way C++ deals with destructors. However, all these constraints go away if destructors are called manually using:
std.typecons.scoped (documentation here)
std.typecons.Unique (documentation here)
destroy on an object manually
delete or scope class (deprecated)
TL;DR There is not much that can safely be done in a class destructor if called by the GC. A solution to this problem is GC-proof resource classes.
It's unclear when and how shared will be implemented.
Virtually noone use shared currently. You are better off ignoring it at this moment.
D accepts trailing commas in every comma-separated list of things.
// Function declarations
void doNothing(
int unusedA,
int unusedB,
)
{
}
// enum declarations
enum
{
whatever,
yolo,
}
// Array literals
static immutable double[] valuesOfPI =
[
22.0 / 7.0,
];
void main()
{
// Function calls
doNothing(
0,
31,
);
// AA literals
string[int] severities =
[
0: "info",
1: "warning",
2: "error",
];
}
When a slice is created with new and a type qualifier, the qualifier applies to pointed elements
instead of the whole slice as would be expected.
import std.stdio;
void main(string[] args)
{
// Output: "const(int)[]"
writeln(typeof(new const(int[4])).stringof);
// Output: "immutable(int)[]"
writeln(typeof(new immutable(int[4])).stringof);
// Output: "shared(int)[]"
writeln(typeof(new shared(int[4])).stringof);
}
Note: this syntax doesn't return pointers to static arrays but indeed return a slice.
This peculiarity was emphasized at DConf 2018 by Andrei Alexandrescu.
DUB is an essential piece of the modern D language experience. However, that experience doesn't include "Running unit tests with optimizations" by default.
So, how do you avoid surprises in production? What would Kent Beck do?
In this post, we unleash the jaleously-guarded secret behind the most successful organizations in the world: running unittests with optimizations ON and OFF.
dub.jsonCreate a new build type with the proper flags. This is also a good way to get to know the discreet "buildTypes".
"buildTypes":
{
"unittest-opt":
{
"buildOptions": ["unittests", "optimize", "inline"]
}
}
Because it doesn't have a -release flag, asserts will still be enabled. Hence, the unittest content is here.
(Please, don't call this configuration unittest-release. Because flag -release not being there is the one important thing. This increase the confusion between "release" and "optimizations").
$ dub test
$ dub test -b unittest-opt
You are now listed in Forbes.
This item is language-agnostic and perhaps the most widely applicable tip on this page.
Being a D programmer requires knowing the two fundamental types of errors in programs.
Similarly to many languages with exceptions, errors are separated in logic errors and runtime errors. This is embodied in the two-headed exception hierarchy:
Error class is for logic errors also known as unrecoverable errors also known as… bugs
Exception class is for runtime errors also known as recoverable errors also known as input errors. But it can also be used for hard-to-classify errors.
Such errors are basically bugs. Logic errors includes but are not limited to:
log(-1) or arccos(2)
The recommended way to deal with these is to throw an Error, for example by using assert. Indeed the only reasonable option when encountering a logic error is to crash. This is how highly reliable system are built: let the OS handle the program crash, let a supervisor restart the faulty process.
If you think you should recover from bugs and keep things running anyway, you are dangerous.
Such errors are basically not bugs:
The canonical way to deal with these is to throw an Exception, for example by using enforce.
Some errors are difficult to classify: what is unrecoverable for a program part might well be recoverable for another. In this case it is recommended to use Exception.
Walter Bright repeatedly explained this item in the D newsgroup:
I believe this is a misunderstanding of what exceptions are for. "File not found" exceptions, and other errors detected in inputs, are routine and routinely recoverable.
This discussion has come up repeatedly in the last 30 years. It's root is always the same - conflating handling of input errors, and handling of bugs in the logic of the program.
The two are COMPLETELY different and dealing with them follow completely different philosophies, goals, and strategies.
Input errors are not bugs, and vice versa. There is no overlap.
See also: http://forum.dlang.org/post/m07gf1$18jl$1@digitalmars.com
std.typecons.Flag like a proFunctions calls with boolean arguments are often hard to read and don't provide meaning.
void doSomething(bool frob);
[...]
doSomething(false); // false what?
Fortunately std.typecons.Flag can help you turn bool arguments into readable flags at no cost.
Buy it now! At your local standard library dealer.
import std.typecons;
void doSomething(Flag!"frob" frob);
[...]
doSomething(No.frob); // ok, no frob. Got it
Use the name Flag!"frob" for the type of the flag
Use Yes.frob and No.frob for the flag values
Do not alias Flag!"frob" to a new name.
For more documentation: https://dlang.org/phobos/std_typecons.html#.Flag
A Voldemort type is simply a type that can't be named by the user.
ae.utils.graphics:template procedural(alias formula)
{
alias fun = binaryFun!(formula, "x", "y");
alias Color = typeof(fun(0, 0));
// Returning auto is necessary here.
// Procedural can't be named outside of the procedural function.
auto procedural()
{
struct Procedural
{
auto ref Color opIndex(int x, int y)
{
return fun(x, y);
}
}
return Procedural();
}
}
Outside of the procedural function of this eponymous template, there is no way to name Procedural. Therefore, Voldemort types can only be passed around in auto variables or auto returns.
Hiding information about types. Because the user can't name or instantiate Voldemort types at will, expressions in a Voldemort lazy computation chain can change types without changing user code.
Voldemort types were promoted and named by Andrei Alexandrescu. They are typically used in chains of lazy computations, like ranges.
See also: Voldemort Types in D
out and ref parameters?Both pass parameters by reference. But out parameters are initialized with .init at function startup, while ref parameters aren't.
import std.stdio;
import std.math;
void functionUsingRef(ref float refParam)
{
writeln(refParam);
}
void functionUsingOut(out float outParam)
in
{
// Initialization for out parameters happens
// before function pre-conditions.
assert(isNaN(outParam));
}
body
{
writeln(outParam);
// Nothing actually forces you to write outParam
// but that's what you should normally do.
// You can also read it's value.
}
void main()
{
float x = 2.5f;
functionUsingRef(x); // Output: 2.5
functionUsingOut(x); // Output: nan
writeln(x); // Output: nan
}
ref and out are storage classes, not type qualifiers. They don't belong to the parameter's type.
"I'm already experienced with C++, Java or C#. I want to ramp up quickly with the best current practices."
Try Learning D by Mike Parker.
"I want examples of feature applications and usage, to see what D enables. Advanced stuff please."
Try the D Cookbook by Adam D. Ruppe.
"I want a whirlwind tour of D."
Try The D Programming Language (TDPL) by Andrei Alexandrescu.
"I want to learn how to program, with D."
Try Programming In D by Ali Cehreli.
"I want to do Web development, with D."
Try D Web Development by Kai Nacke.
Solution: Use the pegged package.
dub.json{
"name": "treewalk-interpreter",
"dependencies":
{
"pegged": "~>0.0"
}
}
source/main.dimport std.conv;
import pegged.grammar;
mixin(grammar(`
Arithmetic:
Term < Factor (Add / Sub)*
Add < "+" Factor
Sub < "-" Factor
Factor < Primary (Mul / Div)*
Mul < "*" Primary
Div < "/" Primary
Primary < Parens / Neg / Number / Variable
Parens < :"(" Term :")"
Neg < "-" Primary
Number < ~([0-9]+)
Variable <- identifier
`));
double interpreter(string expr)
{
auto p = Arithmetic(expr);
double value(ParseTree p)
{
switch (p.name)
{
case "Arithmetic":
return value(p.children[0]);
case "Arithmetic.Term":
double v = 0.0;
foreach(child; p.children) v += value(child);
return v;
case "Arithmetic.Add":
return value(p.children[0]);
case "Arithmetic.Sub":
return -value(p.children[0]);
case "Arithmetic.Factor":
double v = 1.0;
foreach(child; p.children) v *= value(child);
return v;
case "Arithmetic.Mul":
return value(p.children[0]);
case "Arithmetic.Div":
return 1.0/value(p.children[0]);
case "Arithmetic.Primary":
return value(p.children[0]);
case "Arithmetic.Parens":
return value(p.children[0]);
case "Arithmetic.Neg":
return -value(p.children[0]);
case "Arithmetic.Number":
return to!double(p.matches[0]);
default:
return double.nan;
}
}
return value(p);
}
void main(string[] args)
{
assert(interpreter("3 * 1 - (3 + 3) * 4") == -21);
}
Get pegged documentation here.
Get the source code for all DIID examples here.
Solution: Use the arsd-official:dom package.
dub.json{
"name": "parse-xml-file",
"dependencies":
{
"arsd-official:dom": "~>10.0"
}
}
inventory.xml<?xml version="1.0" encoding="UTF-8"?>
<inventory>
<stuff count="5">
<name>melons</name>
</stuff>
<stuff count="8">
<name>lemons</name>
</stuff>
</inventory>
source/main.dimport std.file;
import std.conv;
import std.string;
import std.stdio;
import arsd.dom;
struct Stuff
{
string name;
int count;
}
void main()
{
Stuff[] allStuff = parseStuff("inventory.xml");
// Do things with stuff
foreach(s; allStuff)
{
writefln("%s %s", s.count, s.name);
}
}
Stuff[] parseStuff(string xmlpath)
{
Stuff[] result;
string content = readText(xmlpath);
auto doc = new Document();
bool caseSensitive = true, strict = true;
doc.parseUtf8(content, caseSensitive, strict);
foreach (e; doc.getElementsByTagName("stuff"))
{
Stuff s;
// Parse a mandatory attribute (throw if not there)
s.count = e.getAttribute("count").to!int;
// Parse sub-tags <name>
foreach (e2; e.getElementsByTagName("name"))
{
s.name = e2.innerText.strip; // strip spaces inside <name> myname </name>
}
result ~= s;
}
return result;
}
Get the source code for all DIID examples here.
Solution: Use the requests package.
dub.json{
"name": "get-file-internet",
"dependencies":
{
"requests": "~>2.0"
}
}
source/main.dimport std.stdio;
import requests;
void main(string[] args)
{
auto content = getContent("http://httpbin.org/");
writeln(content);
}
Get requests documentation here.
Get the source code for all DIID examples here.
Solution: Use the arsd-official:jsvar package.
dub.json{
"name": "parse-json-file",
"dependencies":
{
"arsd-official:jsvar": "~>10.0"
}
}
inventory.json{
"stuff":
[
{
"name": "melons",
"count": 5
},
{
"name": "lemons",
"count": 8
}
]
}
source/main.dimport std.file;
import std.stdio;
import arsd.jsvar;
void main(string[] args)
{
var inventory = var.fromJson( cast(string) std.file.read("inventory.json") );
foreach(i, v; inventory.stuff)
{
writefln("Item %s: name = %s count = %s", i, v.name, v.count);
}
}
Get jsvar documentation here.
Get the source code for all DIID examples here.
Solution: Use the game-mixer package.
dub.json{
"name": "play-music",
"dependencies":
{
"game-mixer": "~>1.0"
}
}
source/main.dimport std.stdio;
import gamemixer;
void main(string[] args)
{
IMixer mixer = mixerCreate();
// Obviously you will need a `music.mp3` file in the working directory.
IAudioSource music = mixer.createSourceFromFile("music.mp3");
mixer.play(music);
writeln("Press ENTER to exit...");
readln();
mixerDestroy(mixer);
}
Get the source code for all DIID examples here.
Solution: Use the commonmark-d package.
dub.json{
"name": "md2html",
"dependencies":
{
"commonmark-d": "~>1.0"
}
}
input.md# title
Some **bold** text.
source/main.dimport std.stdio;
import std.file;
import commonmarkd;
void main(string[] args)
{
string text = cast(string) std.file.read("input.md");
text.convertMarkdownToHTML.writeln; // simply writeln the HTML
// CommonMark and Github Flavoured Markdown are supported.
}
Get the source code for all DIID examples here.
Solution: Use the arsd-official:nanovega package.
dub.json{
"name": "accelerated-triangle",
"dependencies":
{
"arsd-official:nanovega": "~>10.0"
}
}
source/main.dimport arsd.nanovega;
import arsd.simpledisplay;
void main ()
{
auto window = new NVGWindow(800, 600, "NanoVega Simple Sample");
window.redrawNVGScene = delegate (nvg)
{
auto W = window.width;
auto H = window.height;
nvg.beginPath();
nvg.moveTo(W*0.5, H*0.24);
nvg.lineTo(W*0.3, H*0.7);
nvg.lineTo(W*0.7, H*0.7);
nvg.fillPaint = nvg.linearGradient(W*0.3, H*0.5, W*0.7, H*0.7,
NVGColor("#f00"), NVGColor.green);
nvg.fill();
};
window.eventLoop(0,
delegate (KeyEvent event)
{
if (event == "*-Q" || event == "Escape")
{
// quit on Q, Ctrl+Q, and so on
window.close();
return;
}
},
);
}
See Nanovega documentation here.
Get the source code for all DIID examples here.
Solution: Use the printed:canvas package.
dub.json{
"name": "pdf-triangle",
"dependencies":
{
"printed:canvas": "~>1.0"
}
}
source/main.dimport std.stdio;
import std.file;
import printed.canvas;
void main(string[] args)
{
auto pdfDoc = new PDFDocument();
IRenderingContext2D renderer = pdfDoc;
with(renderer)
{
// Draw a 50% transparent green triangle
fillStyle = brush("rgba(0, 255, 0, 0.5)");
beginPath(80, 70);
lineTo(180, 70);
lineTo(105, 140);
closePath();
fill();
fillStyle = brush("black");
fillText("That was easy.", 20, 20);
}
std.file.write("output.pdf", pdfDoc.bytes);
}
See the printed API here.
Get the source code for all DIID examples here.
Only 13 bytes are necessary:
void main(){}
You don't necessarily need to write void main(string[] args){}.